B+Tree, root, leaf, level 용어정리
B+Tree는 InnoDB 인덱스의 구조임
데이터가 메모리 크기와 일치하지 않아, 디스크에서 읽어야하는 경우 효율적임
- 트리의 깊이에 따라 요청된 데이터에 엑세스하는데 필요한 최대 읽기 횟수가 고정되어 있어 확장성이 뛰어남
인덱스 트리는 트리에 엑세스하기 위한 시작점으로 root 페이지에서 시작됨
- root page는 InnoDB의 data dictionary에 영구적으로 저장되어 있음
- 트리는 단일 루트 페이지일만큼 작을 수 있고, multi-level tree의 수백만 페이지 일 수 있음
페이지를 leaf(internal)과 non-leaf(node)페이지로 구분함
- leaf 페이지에는 실제 행 데이터가 포함됨
- non-leaf페이지는 다른 non-leaf페이지 또는 leaf 페이지를 가지고 있음
- tree는 균형이 잡혀있고, 모든 가지의 깊이는 동일함
InnoDB는 트리의 각 페이지에 level을 할당함
- 리프페이지에는 level 0을 할당하고, 트리 위로 올라갈수록 level이 증가함
- root page의 level은 트리의 깊이와 같음
- 구분이 중요하지 않은 경우, leaf페이지와 non-leaf페이지는 둘다 internal페이지라고 부름
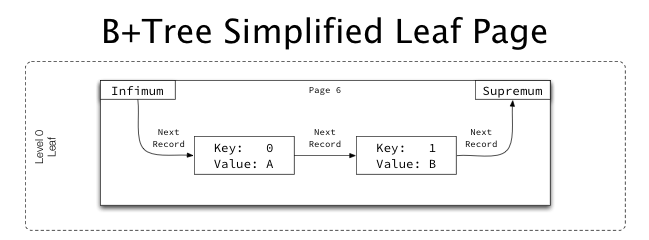
Leaf and non-leaf page
- leaf와 non-leaf페이지(Infimum과 supreme을 포함)는 next record의 오프셋을 저장한 “next record"포인터를 가지고 있음
- 이 연결은 infimum에서 시작하여 모든 레코드를 오름차순으로 연결되며, sumpemum에서 끝남
- 레코드는 물리적으로 정렬되어 있지 않고, 링크된 목록에서의 위치가 유일한 순서임
- insert시 사용 가능한 공간이 있으면 insert됨
- insert시 사용 가능한 공간이 있으면 insert됨
- leaf page의 구조로, 각 레코드의 데이터의 일부로 키가 아닌 값을 가지고 있음
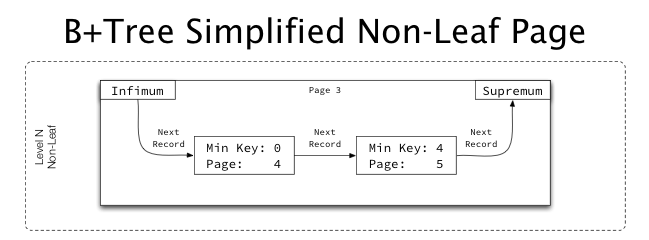
- non-leaf페이지는 동일한 구조를 가지지만, 데이터로 하위 페이지 번호를 가르키며, 정확한 키 대신 하위페이지의 가장 작은 키를 가짐
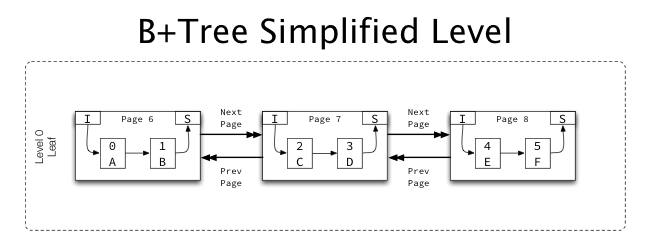
- 대부분의 인덱스는 2개 이상의 페이지로 구성되며, 여러 페이지가 오름차순 및 내림차순으로 링크되어 있음
- 각각의 페이지는 FIL헤더 안에 이전페이지와 다음 페이지를 가르키는 point를 가지고 있음
- 이로인해 INDEX 페이지들은 동일한 레벨에서 double linked list구조를 가짐
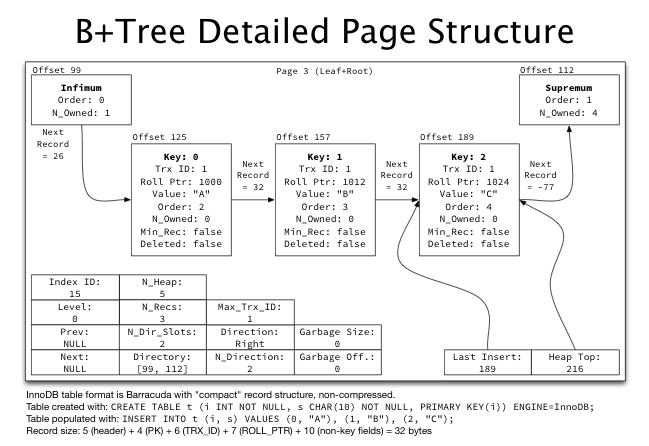
- 위 그림은 B+Tree내의 단일 index page임
실제로 살펴보기
- 실제로 그림에서 사용중인 테스트 테이블을 생성하고, 데이터를 삽입해보자!
| |
- 매우 작고 비현실적이지만, 레코드와 레코드 순회가 어떻게 이루어 지는지 알기 위해 적절한 테이블임
실제 기본 table space 파일 구조 확인
- 실제 테이블을 확인해보면, 이전에 보았던 테이블들과 같이 FSP_HDR, IBUF_BITMAP, INODE 페이지가 있고, 루트 인덱스가 있는 INDEX페이지, 아직 사용되지 않은 FREE 페이지 2개가 존재함
| |
- space-index-pages-summary 명령은 각 페이지에 레코드가 몇개 있는지 알려준다
- 3개가 있을것으로 예상함
| |
실제 레코드 확인
| |
- :format
- 레코드가 Barracuda 포맷 테이블 내의 compact포맷인것을 의미
- 반대로 Antelope 테이블 내의 redundant가 있음
- 레코드가 Barracuda 포맷 테이블 내의 compact포맷인것을 의미
- :key
- 인덱스의 키 필드 배열
- :row
- 키가아닌 필드의 배열
- :transaction_id and :roll_pointer
- 각 레코드에 포함된 MVCC를 위한 내부 필드
- :header내의 :next
- 실제로는 상대저 오프셋(32)가 들어가며, 편의를 위해 계산된 오프셋이 표시됨
인덱스 재귀
- index-recurse모드를 사용하면 전체 인덱스를 재귀하는 멋지고 간단한 출력을 얻을 수 있음
- 예시는 단일 페이지 인덱스이므로 매우 짧음
| |
간단하지 않은 인덱스 트리 구축
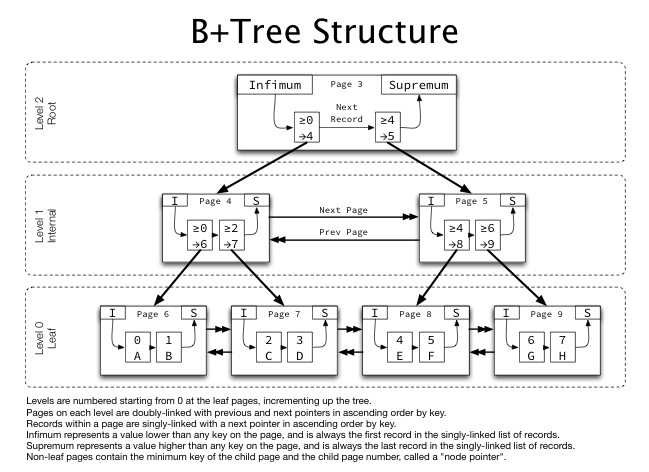
- multi level 인덱스는 위와같이 나타남
- 이전에 설명했듯이, 모든 페이지는 각각 doubly-linked 되어있고, 각 페이지 안의 레코드들은 오름차순으로 singly-linked되어있음
- Non-leaf페이지는 실제 키보다는 자식의 페이지 넘버를 포함한 포인터를 가지고 있음
| |
- 10만개의 row를 가지는 간단한 테이블은 위와같은 구조리르 가짐
- ROOT, INTERNAL, LEAF NODE를 가지고 있음
- 일부 페이지는 완전히 꽉차있으며, 468개의 레코드가 16KB페이지의 거의 15KB를 차지하고 있음을 알 수 있음
| |
- 위는 non-leaf 페이지임
- :key 배열이 나타나고, 정확한 키보다는 자식레코드의 최소키를 포함하고 있음
- :row 필드가 없으며, child_page_number가 해당 필드를 대신함
특별한 root page
- 인덱스가 처음 생성될때 루트페이지가 할당되고, 해당 페이지 번호가 데이터 사전에 저장되므로 루트페이지는 절대 재배치하거나 제거할 수 없음
- 루트페이지가 가득 차면, 루트페이지와 두개의 리프 페이지로 구성된 작은 트리를 형성하여 분할해야함
- 하지만 루트 페이지 자체는 재배치 할 수 없으므로 분할할 수 없음
- 대신 새 빈페이지가 할당되고, 루트 레코드가 그 페이지르 이동되며(루트페이지가 한단계 상향됨) 새페이지가 두개로 분할됨
- 그러면 루트페이지는 바로 그 아래 레벨에 하위페이지(node pointer라 부름)로 가득 찰 때까지 다시 분할할 필요가 없으며, 실제로 수천개의 페이지가 될 수 있음
https://blog.jcole.us/2013/01/10/btree-index-structures-in-innodb/