- document의 문자열 필드가 역 인덱스의 term으로 변환되는 방식을 결정하는 알고리즘
- 궁극적인 목표는 문자열을 일련의 토큰으로 변환하는것
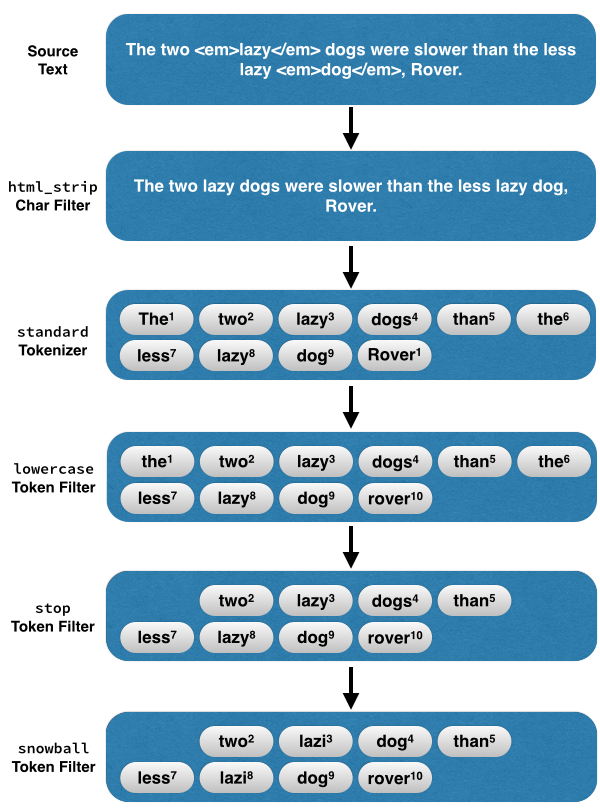
문자열이 token화 되는 과정

1. Input
2. CharacterFilter
- 텍스트를 소문자로 변환하거나, 단어를 대체하는 등 특정 방식으로 문자열을 변환하고, 변환된 문자열을 출력함
- 문자를 추가, 제거, 또는 변경함
- 힌두-아랍 숫자(٠١٢٣٤٥٦٧٨٩)를 아랍어-라틴어(0123456789)로 변환하거나 <b>와 같은 HTML 요소를 제거할 수 있습니다.
3. Tokenizer
- 문자열 스트림을 입력으로 받아, 개별 토큰으로 분리함
- 다음을 데이터을 저장
- 각 용어의 순서 또는 위치
- 용어가 나타나는 원래 단어의 시작 및 끝 문자 오프셋
- 검색 스니펫을 강조하기 위해 사용함(?)
- 토큰 유형
- ex)
<ALPHANUM>,<HANGUL>, or<NUM>
- ex)
4. TokenFilter
- Tokenizer에서 받은 토큰을 수정(대->소 문자로 변환), 삭제(stopword제거), 추가(ex) 동의어)함
5. Output
https://www.elastic.co/blog/found-text-analysis-part-1
https://www.elastic.co/blog/found-text-analysis-part-2
https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-charfilters.html
https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-tokenizers.html