- search쿼리는 도착지를 고정할 수 없고, 잠재적으로 매칭되는 index또는 indices안의 모든 샤드를 검색해야하기에 어려움
- 일치하는 문서를 찾는 것 뿐만아니라, 검색 api는 결과를 사용자에게 표시하기 전에 통합되고 정리된 목록으로 결합해야함
- 기본적으로, 엘라스틱서치는 Query Then Fetch라는 검색방법을 사용함
단계
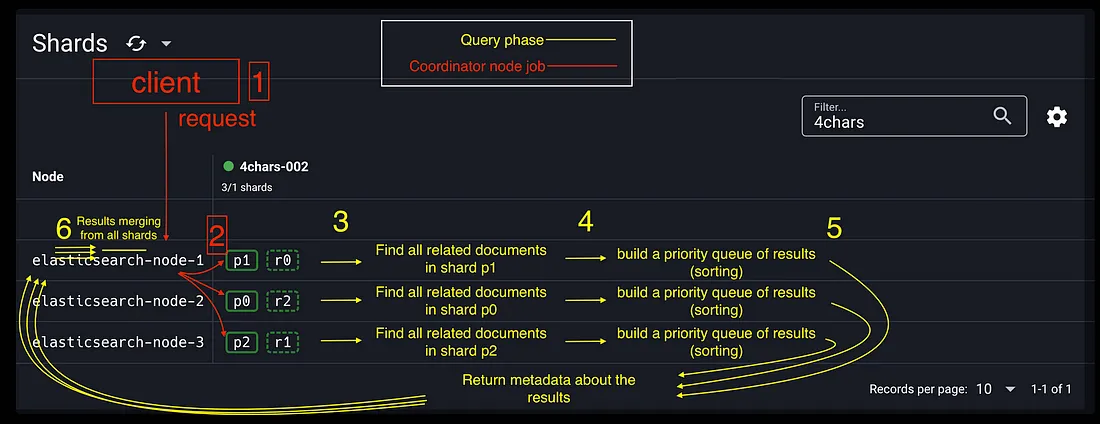
1. 클라이언트가 Elasticsearch로 쿼리 전송(조정노드)
2. 쿼리를 각 샤드로 브로드캐스팅(조정노드)
2-1. 조정노드는 패턴 또는 별칭으로 대상 인덱스 목록 작성
- 단일인덱스도 될 수 있지만, logsash-*과같이 패턴일 수 있음
- 실제 쿼리가 검색해야하는 인덱스 목록이 생성됨
2-2. 대상 인덱스의 distinct shard 목록을 작성함 - distinct shard목록은 primary shard와 replica shard의 집함임
- 검색요청은 primary shard와 replica shard 둘 중 어
2-3. 각 인덱스의 라우팅옵션에 따라 모든 샤드로 갈지, 하나의 샤드로 갈지 결정함 - 대부분의 쿼리는 모든 별개의 샤드로 가지만, 특정 라우팅으로 하나의 샤드에 모든 document가 있다는것을 보증한다면, 하나의 샤드로만 쿼리함
2-4. 조정노드는 관롼된 각 샤드에 대해 쿼리할 실제 샤드를 선택함 - 일반적으로 무작위로 선택되지만, 최근 쿼리에서 가장 성능이 좋은 샤드를 결정하는 등 최적화가 이루어지기도 함
3. 로컬 용어/빈도를 사용해 일치하는 모든 문서 찾기 및 점수계산
- 아래의 작업이 발생함
- ElasticSearch level에서 매핑
- 인덱스 시점의 매핑과 유사함
- 쿼리 필드를 기본 Lucoene데이터 필드 및 구조에 매핑하여, 각 세그먼트(Lucene index)가 실행할 수 있는 Lucene호환 쿼리를 생성
- Lucene에서의 분석
- Lucene에서 검색
- Lucone에서 Scoring
- ElasticSearch level에서 매핑
- 쿼리의 텍스트 부분은 동일한 analyzer를 통해 tokenzing됨
- 이로인해 쿼리 텍스트가 색인된 방식과 일치하게 됨
4. 결과의 우선순위 큐 구축(정렬, 페이지네이션 등)
5. 조정 노드에 결과에 대한 메타데이터를 반환함
- 실제 문서가 아닌 document ID와 점수를 반환함
6. 모든 샤드의 점수가 조정 노드에서 병합 및 정렬되고, 쿼리 기준에 따라 문서가 선택됨
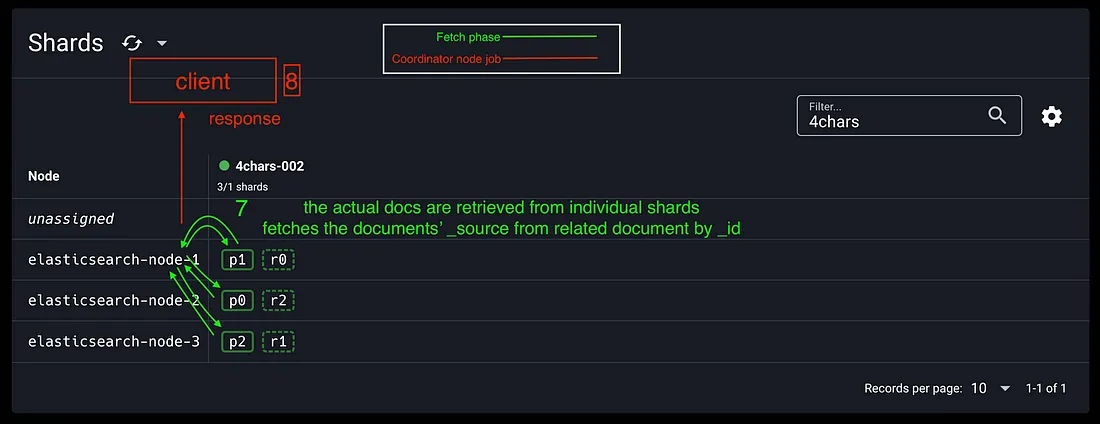
7. 끝으로, 실제 문서가 있는 개별 샤드에서 실제 문서가 검색됨
8. 결과를 클라이언트에 반환(조정노드)
- 조정 노드는 1,2,8단계에서 사용됨
Query Phase(3,4,5,6)
- 검색 쿼리는 모든 샤드에 전성되어 로컬 실행이 시작되고, 일치하는 문서가 포함된 우선순위 대기열이 생성됨
Fetch Phase(7)
query Phase가 연관된 문서를 확인하는 반면에, Fetch phase에서는 각각의 샤드에서 실제 문서를 가져오는 역할을 담당함
이 분할방식은 분산된 환경에서 효과적이고 확장가능한 검색작업을 보장함
- Query phase에서는 검색 커리가 각 샤드 복사본을 탐색하여 로컬 검색을 시작하고, 일치하는 문서의 우선순위가 지정된 목록을 컴파일함
- 이 단계는 검색 결과를 구체화 하는 초기단계임
- Fetch phase에서는 원하는 검색 결과를 제공함
- 이 단계는 쿼리 실행과 검색 결과 사이의 가교 역할을 하며 검색 프로세스의 철저함을 보장함
- Query phase에서는 검색 커리가 각 샤드 복사본을 탐색하여 로컬 검색을 시작하고, 일치하는 문서의 우선순위가 지정된 목록을 컴파일함
추가 정보
- Elasticsearch의 query와 fetch phases에서 slow logs를 enable하면, 검색 성능을 모니터링 및 최적화가 가능함
| |
https://medium.com/@musabdogan/elasticsearchs-distributed-search-query-and-fetch-phases-df869d35f4b3
https://steve-mushero.medium.com/elasticsearch-search-data-flow-2a5f799aac6a