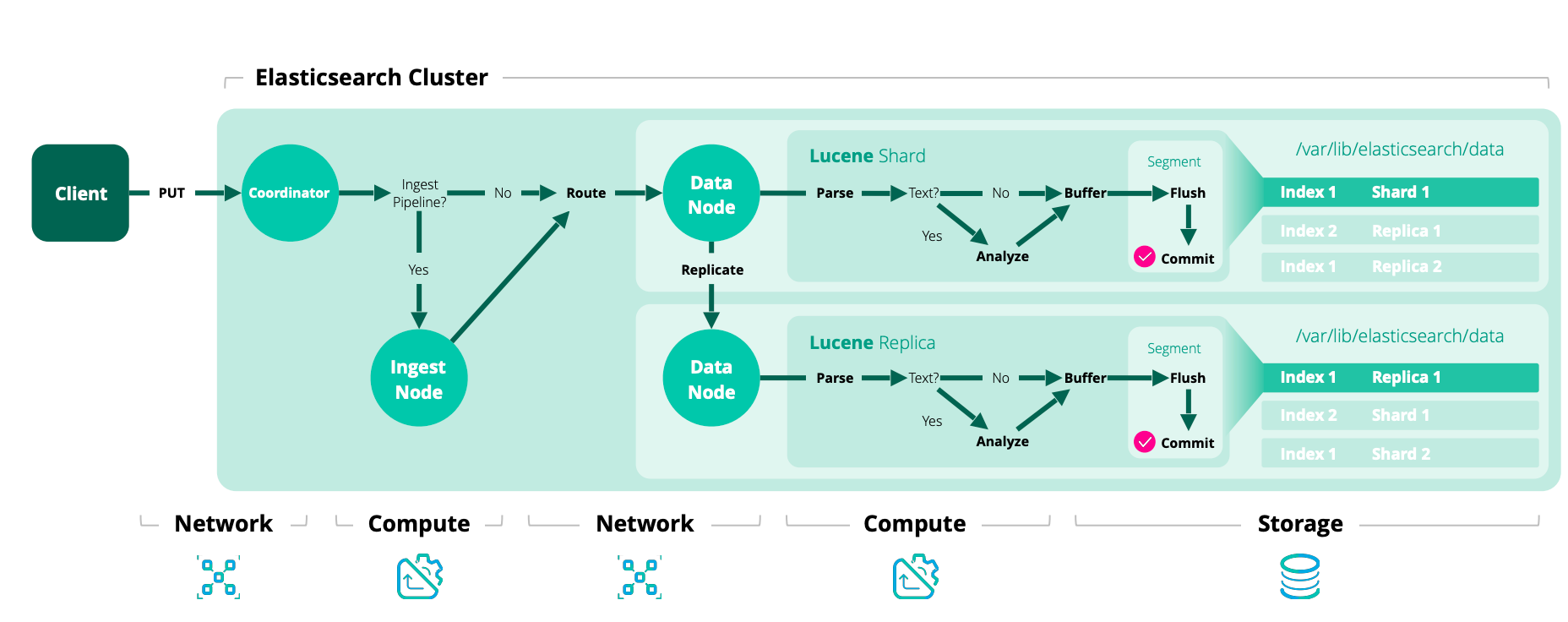
1. coordinateing stage
- Elasticsearch의 모든 색인 작업은 일반적으로 document ID(routing_key)를 기반으로 라우팅을 사용해 복제 그룹을 확인함
shard = hash(routing_key) % number_of_primary_shards
- 복제 그룹이 확인되면, 그 작업은 내부적으로 그룹의 현재 기본 샤드로 전달됨
2. primary stage
- primary 샤드는 작업의 유효성을 검증하고, replica 샤드로 전달하는 역할
- replica 샤드는 오프라인 상태일 수 있으므로 primary 샤드가 모든 replica에 복제할 필요가 없음
- 대신 Elasticsearch는 작업을 수신해야 하는 샤드 복제본 목록을 유지함
- 이 목록을
in-sync copies라고 불리며, 마스터노드에서 관리됨 - 사용자에게 승인된 모든 인덱스 및 삭제 작업을 처리했음을 보장하는 정상 샤드 복사본 직합
- primary는 이 불변성을 유지할 책임이 있으므로, 모든 작업을 해당 세트의 replica에 복제해야함
- 기본 샤드의 요청 흐름
2-1. 들어오는 연산의 유효성을 검사하고, 유효하지 않은 경우 거부함
ex) 숫자 필드에 객체 필드가 들어오는경우
2-2. local에서 작업을 수행하고, 관련 document를 indexing하거나 삭제함- 유효성을 검사하고 필요할경우 거부함(키워드가 너무 길어 Lucene에 색인할 수 없는경우)
2-3. in-sync copies set의 각 replica에게 작업을 전송함 - 복제본이 여러개인 경우, 병렬로 수행됨
2-4. 모든 in-sync copies set이 작업을 성공적으로 수행하고, primary에 응답하면 primary는 클라이언트에 대한 요청이 정상적으로 완료되었음을 알 수 있음
- 유효성을 검사하고 필요할경우 거부함(키워드가 너무 길어 Lucene에 색인할 수 없는경우)
검색은 in-sync copies에 있는 reaplica샤드 뿐만아닌, 모든 replica 샤드에서 검색이 가능함
모든 replica샤드에 요청이 전파되어 저장되기 전에, in-sync copies외 샤드에 검색하면 변경내용이 없음
이로인해 es는 near real-time search가 됨
3. replica stage
- 각 in-sync replica는 로컬에서 인덱싱 작업을 수행하며 복사본을 가짐
위의 indexing단계는 순차적으로 진행되며, 내부 재시도를 가능하기 위해 lifetime을 가지고 있음
https://www.elastic.co/blog/found-elasticsearch-top-down
https://www.elastic.co/blog/found-elasticsearch-from-the-bottom-up
https://www.javaadvent.com/2022/12/elasticsearch-internals.html
https://www.elastic.co/guide/en/elasticsearch/reference/current/docs-replication.html#basic-write-model
https://www.elastic.co/guide/en/elasticsearch/reference/current/near-real-time.html