Java 언어의 특징
- Java는 컴파일 + 인터프리터 두가지 특징을 다 가지고 있음
- Java코드를 컴파일하면 .class파일(byte Code)이 되고, JVM은 .class파일을 가지고 os에 맞게 machine code로 변환함
- .class파일은 특정 실행횟수가 지나면 최적화가 됨
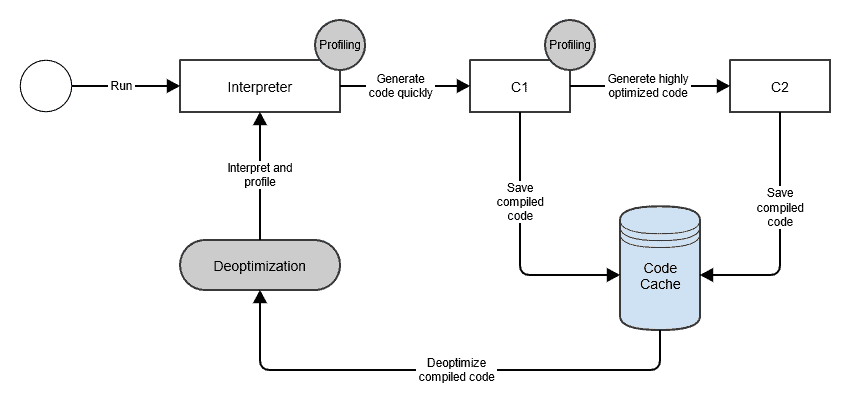
Tiered Compilation
- JVM의 JIT Compiler는 자주 실행되는 부분의 코드를 native code로 변환함
- JIT compiler에는 2개의 java byte code interpreter가 존재함
- Client compiler
- 메소드를 빠르게 컴파일 하지만 Server compiler보다 덜 최적화된 machine code를 생성함
- 빠른 시작에 사용함
- Server compiler
- 동일한 메서드르 컴파일하는데 더 많은 시간이 듬
- Client compiler보다 더 많은 시간 및 메모리를 소요하지만, 더 최적화된 machine code를 생성함
- Client compiler
- Tiered Compilation은 Client compiler를 첫번째 계 으로 사용하여 서버 VM시작 속도를 향상시킴
- 서버 vm은 인터프리터를 사용하여 컴파일러에 공급되는 메서드에 대한 프로파일링 정보를 수집함
- Tiered Compilation에서는 인터프리터 외에도 client compiler가 자신에 대한 프로파일링 정보를 수집하는 메서드의 컴파일된 버전을 생성함
- 컴파일된 코드가 인터프리터 보다 후러씬 빠르기 때문에, 이 프로파일 단계에서 프로그램이 더 뛰어난 성능으로 실행됨
- 애플리케이션 초기화 된계에서 server compiler가 생성한 최종 코드를 사용할 수 있기때문에 시작이 더 빠른 경우도 종종 존재함
Tier level
- 서로 다른 컴파일러와 인터프리터의 결합으로 아래와 같은 5개의 최적화 수준이 생성됨
| Level | Compiler | |
|---|---|---|
| 0 | Interpreter | JVM은 모든 자바 코드를 0 level을 사용함 워밍업 단계가 끝나면 JIT 컴파일러가 시작되어 런타임에 코드를 최적화함 JIT 컴파일러는 0 level에서 수집한 프로파일링 정보로 최적화 수행 |
| 1 | C1 without profiling | C1컴파일러를 사용하여 코드를 컴파일하지만, 프로파일 정보는 수집하지 않음 사소한 것으로 간주되는 메서드(ex. getter)에 대해 level1 컴파일을 수행함 메서드 복잡성이 낮아 C2컴파일하지 않음 |
| 2 | C1 with basic profiling | JVM은 라이트 프로파일링이 포함된 C1컴파일러를 사용하여 컴파일함 C2큐가 가득차면 level2를 사용함 목표는 성능개선을 위해 가능한 빠르게 코드를 컴파일 하는것 나중에 JVM은 전체 프로파일링을 사용하여 level3으로 코드를 다시 컴파일함 마지막으로, C2 대기열이 짧아지면, JVM은 level4에서 코드를 다시 컴파일함 |
| 3 | C1 with full profiling | JVM은 전체 프로파일링이 포함된 C1컴파일러를 사용하여 코드를 컴파일함 level3은 기본 compilation path임 JVM은 사소한 메서드와 컴파일러 대기열이 가득찬 경우를 제외한 모든 경우에 사용함 JIT컴파일러에서 가장 일반적인 시나리오는 해석된 코드가 레벨 0에서 레벨3으로 바로 점프하는 것임 |
| 4 | C2 full optimizing, no profiling | 장기적인 성능을 극대화 하기 위해 JVM이 C2컴파일러를 사용하여 코드를 컴파일함 level 4는 기본 compilation path임 JVM은 사소한 메서드를 제외한 모든 메서드를 level4로 컴파일함 level4코드는 완전히 최적화된 것으로 간주되므로 프로파일링 정보 수집을 중단함 그럼에도, 코드 최적화를 해제하고 레벨 0으로 돌려보낼 수 있음 |
- 일반적으로 메서드는 interperter안에서 생성되며 메서드가 실행되는동안 계측을 통해 메서드의 프로파일이 수집됨
- 수집된 프로파일은 휴리스틱에 의해 사용되며 컴파일될지, 다시 다른 수준에서 컴파일 될지, 어떤 최적화를 수행할지 절정함
- 메서드를 실행하는 동안 HotSpot이 수집하는 가장 기본적인 두 가지 정보는 메서드가 실행된 횟수와 메서드의 루프가 반복된 휫수임
- 이 정보는 컴파일 정책에서 메서드를 컴파일 할지 여부와 컴파일 수준을 결정하는데 사용됨
- 컴파일 정책에서는 현재 compile중인 메서드에 대해 컴파일 요청을 레벨 3에서 설정하기 위해 공식을 사용함
- 현재 3레벨 컴파일로 실행중인 메서드를 레벨 4로 컴파일 하기 위한 요청을 생성할지 여부를 결정하는 데도 동일한 공식이 사용됨
| |
TierXInvocationThreshold
- 호출 수가 이 임계값을 초과하는 경우, 메서드를 레벨X로 컴파일함
- 기본값은 레벨 3의 경우 200, 레벨 4의 경우 5000
TierXMinInvocationThreshold
- 메서드를 레벨 X에서 컴파일하는데 필요한 최소 실행 횟수
- 기본값은 레벨 3의 경우 100, 레벨 4의 경우 600
TierXCompileThreshold
- 메서드와 해당 루프의 반복 횟수가 이 임계값보다 . 더많이 실행된 경우 메서드를 레벨 X에서 컴파일함
- 기본값은 레벨 3의 경우 2000, 레벨 4의 경우 15000
Executions
- 메서드가 실행된 횟수
Iterations
- 메서드 내부의 루프가 실행된 누적 반복 횟수
Scale
- 컴파일 대기열 부하를 안정적으로 유지하기 위한 Scale 계수
- 컴파일 대기열 함목 수와 컴파일러 스레드 수에 따라 주기적으로 동적으로 조정됨
HoptSpot은 컴파일이 다른 부분에 미치는 영향과 시스템이 현재 처리하고 있는 부하량도 고려함
메서드를 해석중이고 위의 공식이 충족되어 레벨 3에서 메서드를 컴파일한다고 가정하면 컴파일 정책이 실제로 레 3이 아닌 레벨2에서 컴파일 하기로 결정할 수 있음
- C2 대기열의 길이
- 일반적으로 레벨 3에서 컴파일된 메서드는 레벨2에서 컴파일된 동일한 메서드보다 느리기 때문에 메서드가 레벨3에서 보내는 시간을 최소화 하는 것이 좋음
- 적절한 프로파일리을 수집하여 필요한 시간만 레벨 3에서 소비해야함
- 따라서 C2대기열이 너무 길어, 레벨 3로 전환되는게 너무 오래걸린다면 우선 레벨 2로 이동하는 것이 유리함
- 추후 C2대기열이 줄어든다면 레벨 3에서 메서드를 다시 컴파일함
- C1대기열 길이는 임계값을 동적으로 조정하고, 컴파일러가 과부하 될때 추가 필터링을 도입하는데 사용됨
- 컴파일러 대기열이 너무 길면 컴파일이 완료될 때 까지 메서드가 더이상 실행되지 않을 수 있기 때문
- C2 대기열의 길이
레벨 3에서 컴파일된 메서드가 레벨 4로 전환하기 위한 공식을 충족할 만큼 충분하 실행되면, 해당 레벨에서 메서드를 다시 컴파일 하라는 요청이 생성됨
이 level에서는 HotSpot은 장기적인 성능을 극대화 하기 위해 C2 컴파일러를 사용하여 코드를 컴파일함
레벨 4코드는 완전히 최적화된 것으로 간주되므로 JVM은 프로파일링 정보 수집을 중단함
위 설명은 컴파일 정책의 단순화된 버전임, 메서드를 컴파일하거나 다시 컴파일할지 결정할 때 HotSpot이 고려하는 몇가지 다른 사항과 JVM 사용자가 정책을 정의하는데 사용할 수 있는 몇개의 플래그가 있음
- 아래는 최적화와 연관된 이야기임
C2는 메소드의 동적 프로파일에 대한 정보를 사용하여 몇가지 최적화를 안내함
- Inlining, Class Hierarchy Analysis(CHA), basic block ordering, some loop optimizations
프로파일이
if-else문이 과거에then부분만 실행했음을 보여줄 떄,- C2는 앞으로도 계속 이런 일이 발생할 것이라 가정하고,
else블록은 전혀 컴파일 하지 않기로 결정
- C2는 앞으로도 계속 이런 일이 발생할 것이라 가정하고,
프로파일이 참조 변수가 절대 null이 아니라고 보여줄 때,
- C2는 향후 실행에서 변수가 계속 null이 아닐것이라고 가정하고, 그 가정을 사용하여 코드를 최적화 할 수 있음
프로필이 루프가 일반적으로 수천번 반복된다고 보여줄 때,
- C2는 해당 정보를 기반으로 루프를 unrolling 또는 벡터화 할 수 있음
프로파일이 클래스에 서브클래스가 없음을 보여줄 때,
- C2는 해당 클래스의 객체를 사용하여 메서드 호출에서 인라인 또는 다른 종류의 최적하를 수행하기로 결정할 수 있음
메서드의 프로파일은 동적 문제가 있음
애플리케이션이 실행동항 메서드의 프로파일이 안정적일것이라는 보장은 없음
- 프로그램 실행 중 대부분 참이었던
if-else조건이 갑자기 거짓을 반환함 - 트리거 되지 않었던 예외가 트리거됨
- 한번도 null이 아니었던 참조변수가 null로 표시됨
- 시스템에 새클래스가 로드되고, 이전에는 단순했던 클래스 계층구조가 더 복잡해짐
- 일반적으로 수천번 반복되는 루프가 이제는 몇번만 반복함
- 프로그램 실행 중 대부분 참이었던
이러한 동적 동작을 고려하기 위해, C2는 컴파일된 코드에 predicates를 삽입하여 프로파일 정보를 기반으로 한 가정이 예전이 유효한지 확인함
predicate가 false인 경우, 트랩(JVM 내부에 대한 호출)이 실행되어 어떤 가정이 거짓인지 HotSpot에 알림
트랩이 제공한 정보를 바탕으로 HotSpot은 수행해야 할 작업을 결정함
현재 컴파일된 메서드를 다시 컴파일할 수 있고, 실행을 인터프리터로 전환해야 할 수도 https://github.com/openjdk/jdk/blob/8eed7dea7b92dd98b74277e8521100f7f807eabb/src/hotspot/share/runtime/deoptimization.hpp#L69
트랩이 실행될 수 있는 가능한 이유 목록 링크
- 필요한 조치목록링크
- 필요한 조치목록링크
Compile 관련 옵션
default로 TieredCompilation은 활성화 되어있음
-Xcomp
- 메서드를 컴파일만 하도록 설정
- HotSpot은 인터프리터를 사용하지 않으며 메서드는 항상 컴파일됨
-Xint
- 메서드를 인터프리터만 사용하도록 수정
- 모든 JIT컴파일러가 비활성화되고 HotSpot이 프로그램을 실행하는 유일한 수단은 interpretation임
-XX:TieredStopAtLevel
- 최대 컴파일 수준을 설정하는데 사용함
- 일부 C2버그를 우회하거나 C1을 스트레스 테스트 하기 위해 C1컴파일러만 사용하도록 강제하는것
-XX:-TieredCompilation
- HotSpot이 Tiered Compilation heuristics을 사용하여 컴파일간 전환하지 않고, 다른 heuristics을 사용하여 모든 컴파일에 대해 C1과 C2를 선택하게함
- XX:InitialCodeCacheSize=N
- XX:ReservedCodeCacheSize=N`
-XX:NonNMethodCodeHeapSize
- non-method segment 영역을 지정
- JVM내부 관련코드(default 대략 5MB)
-XX:ProfiledCodeHeapSize
- profiled-Code segment 영역 지정
- C1으로 컴파일된, 잠재적으로 짧은 수명을 가진 영역(default 대략 122MB)
-XX:NonProfiledCodeHeapSize
- non-profiled-code segment 영역 지정
- C2로 컴파일된, 잠재적으로 긴 수명을 가진 영역(default 대략 122MB)
-XX:Tier4CompileThreshold
- Tier4로 컴파일 하는 Threshold를 지정
-XX:+PrintCompilation
- default로, JIT compilation log는 disable되어 있음
- 위 옵션으로 JIT compilation log를 활성화 할 수 있음
- 아래의 포맷을 가짐
- Timestamp
- 애플리케이션 시작 . 후밀리초 단위
- Compile ID
- 컴파일되 각 메소드의 increment ID
- Attribute
- 5가지 값의 상태를 가짐
- % - 온스택 교체 발생
- s - 메소드가 동기화됨
- ! - 메소드가 exception handler를 포함하고 있음
- b - blocking모드에서 컴파일이 발생
- n - 컴파일이 래퍼를 네이티브 메서드로 변환함
- 5가지 값의 상태를 가짐
- Compilation level
- 0에서 4사이 값을 가짐
- Method name
- Bytecode size
- Deoptimisation indicator
- Made not entrant
- 표준 C1 최적화 또는 컴파일러의 낙관적 가정이 잘못된것으로 이증되을때
- Made zombie
- 코드캐시에서 공간을 확보하기 위해 gc의 정리 메커니즘
- Made not entrant
- Timestamp
아래는 AMD Ryzen 7 1800X machine running Ubuntu 20.04에서 java-17.07으로 HelloWorld 프로그램을 실행한 결과임
| Flags | Average Wall Time |
|---|---|
| “Default” | 0.020s |
| -Xint | 0.020s |
| -Xcomp | 0.890s |
- -Xcomp로 실행한것이 현저하게 느린것을 확인할 수 있는데, 이는 많은 메서드가 컴파일 비용을 상쇄할만큼 충분히 실행하지 않았기 때문
- 인터프리터만 사용하도록 JVM을 구성하면, 사용자 지정을 하지 않았을때와 같은데, 이는 예제가 오래 실행되는 메서드가 없기에, 인터프리터가 최선의 선택이기 때문임
https://www.baeldung.com/jvm-tiered-compilation
https://docs.oracle.com/en/java/javase/11/jrockit-hotspot/compilation-optimization.html#GUID-8033B236-F6E5-473B-BB9F-34422143A1AA
https://devblogs.microsoft.com/java/how-tiered-compilation-works-in-openjdk/